Introducción
El siguiente post, por su propio titulo lo indica, es la segunda parte del post 'Contar Olivos con Ortofoto: Parte I'.
En esta segunda parte, se trata de ver que métodos o de que forma se puede discriminar, que son olivos y que no son, para de esta forma tener el número de olivos de una ortofoto con el menor margen de error (+- 4 olivos creo que es un margen razonable¿?):
Nota: para quién quiera ver los olivos que tiene cada recinto, una herramienta que puede utilizar es el SIGPAC (Sistema de Información Geográfica de Identificación de Parcelas Agrícolas).

Nota: para quién quiera ver los olivos que tiene cada recinto, una herramienta que puede utilizar es el SIGPAC (Sistema de Información Geográfica de Identificación de Parcelas Agrícolas).

Redes Neuronales
Utilice redes neuronales con una capa oculta, pero no era capaz de aprender con un margen de error mínimo.
Como un olivo puede estar representado por diferentes tamaños en pixeles. Por ejemplo, 20x20, 15x15, 4x4,..etc..lo que se hacía, era pasar todas las imagenes a un tamaño fijo, 7x7. Con este tamaño, las muestras de olivos, y las muestras de no olivos, para que aprendiese la red neuronal, daba un error grande, y no aprendía bien. Era por que la diferencia entre las imagenes de los olivos y los que no eran olivos, era muy pequeña.
Es posible, con ortofotos de alta calidad, donde un olivo puede ser representado por tamaños de 50x50, se pueda usar una red neuronal.¿?. Ya que la diferencia ahora, entre una imagen de lo que es un olivo y lo que no, se diferencian más.
Entonces, ¿qué usar?
Clustering k-means
Para una mejor explicación, ver Clustering k-means. Y a mi modo de ver, este algoritmo lo que hace es que dado un número determinado a priori de clusters, el algoritmo, va mirando si los valores de un elemento, un objeto, está más cerca de un cluster o de otro. Y encuentra un cluster que este más cerca, asigna ese objeto a ese cluster. Creo que no está muy bien explicado. En el caso concreto que nos atañe.
Se han identificado por ejemplo 100 posibles olivos de diferentes tamaños (5x5, 20x20,..etc). Ahora, el algoritmo, inicializa aleatoriamente, los clusters a los que pertenece cada objeto. Es decir, va diciendo..."objeto 1 tu perteneces aleatoriamente al cluster 0, tu el objeto 2, al cluster 3,...hasta 6 clusters".
Luego se calcula el centroide de cada cluster. El centroido sera el tamaño medio de los objetos que lo componen.
Y luego ya por ultimo, entramos en el 'while'. Que será, mientras haya cambio de un objeto de un cluster a otro, se hace: se va por cada objeto, y se mide la distancia (distancia de Euler) de ese objeto a todos los cluster, si se encuentra que el cluster más cercano encontrado, es distinto al que pertenece el objeto, eureka!, el objeto no pertenece a ese cluster y se pasa al otro.
Al final del algoritmo, en este ejemplo, tenemos 6 clusters, y cada uno con objetos similares entre sí.
Aquí, se supone que como los olivos serán casi todos del mismo tamaño, estarán casi todos en un mismo cluster, y los objetos que no son olivos, en otro clusters distinto.
Veamos un pantallazo.
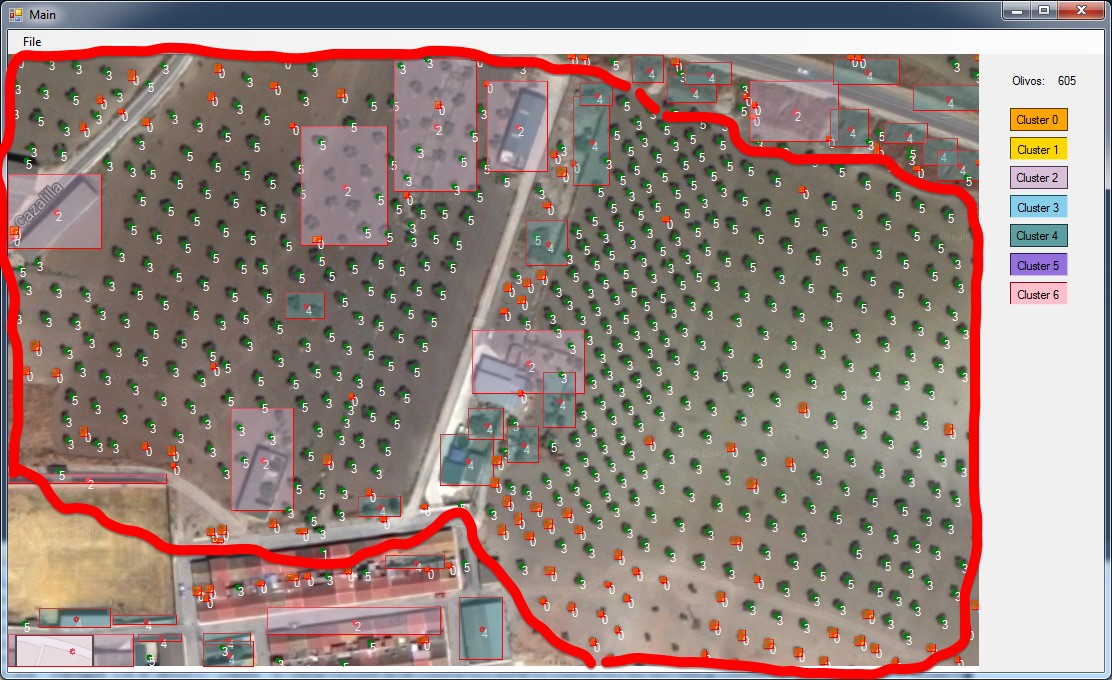
Ene el pantallazo se ven rectangulos semitransparentes. Esto son cluster que se han determinado que no entran a formar parte del computo de la suma de los olivos. Y como se van son rectangulos que no tienen nada que ver con un olivo.
Pero, aquí está el problema que veo, que hay objetos en un cluster, que son olivos y otros que no son. Por ejemplo, el Cluster 5, son olivos, pero luego hay etiquetas 5 en el tejado de una casa.
¿como solucionar esto?
Un solución rápida, sería que el usuario, definiera una región de la ortofoto, donde se le diga, donde debe contar, y los objetos que estén fuera de esta región (la marcada por el trazado rojo), no entrar en el conteo de los olivos.
El trazado rojo, está dibujado con el Paint, y no ha sido implementado en el programa, pero no sería un ejercicio complicado el crear una región y aplicar clipping.
Conclusión
No ha sido muy elegante la solución, por el hecho de tener que dibujar una región, pero si por lo menos para una primera versión, si contaría los olivos correctamente. Ahorrando los costes de llevar personal para que los cuente (tiempo, viajes, dietas,....).
El programa en release está aquí.
Félix Romo
felix.romo.sanchezseco@gmail.com
Muy buen post, enhorabuena!!
ResponderEliminarHola, no sé si hay una versión más actualizada del software o si lo ha retirado del post, pero da un HTTP 404 en el enlace de descarga
ResponderEliminar